食品検査のことなら
ビジョンバイオ
コラム
データベース規模から考える【米品種判別検査】の選び方
2026年5月28日
DNA検査の精度を左右する「データベース」の重要性とは?
DNA検査というと、「DNAが一致した=正しい判定ができた」と考えられがちです。
しかし実際には、それだけでは十分とは言えません。DNAによる品種判別では、
「目的のものと一致すること(同一性)」 「目的のもの以外とは一致しないこと(排他性)」
この2つを同時に確認することが重要です。特に見落とされやすいのが、後者の「排他性」です。
“一致した”だけでは不十分?
たとえば、ある試料Xについて「品種10であるか」を確認する際に、下記のようにA(50品種)、B(30品種)の2種類のデータベースがあるとします。
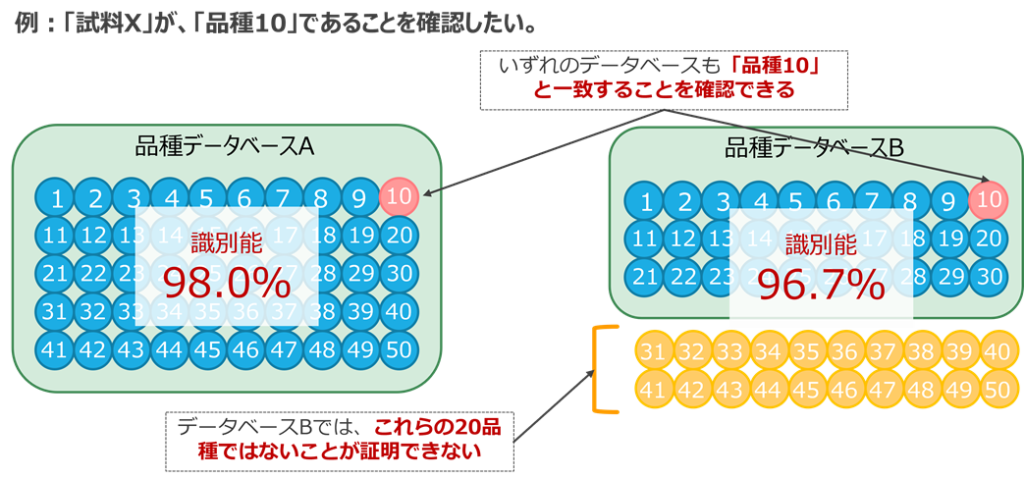
「品種10」は、AとBの両方のデータベースに登録されているので、どちらでも「品種10と一致した」という判定(同一性の確認)は可能です。
しかし、「排他性」についてはどうでしょうか。
データベースAでは、「試料Xは、残り49品種とは異なる」ことまで確認できます。
一方、データベースBでは、「29品種とは異なる」ことの確認にとどまり、登録のない20品種については、異なるかどうかの証明はできません。
つまり、「品種10らしい」という判定はできても、「本当に他の品種ではない」と言い切れる範囲に差が生じるのです。
データベース規模が“識別能”を決める
DNA検査の精度は、検査手法そのものだけでなく、比較対象となるデータベースの充実度によっても大きく左右されます。
登録品種数が多いほど、
・ より多くの候補を除外できる
・ 誤判定リスクを低減できる
・判定の信頼性が高まる
というメリットがあります。
特に米穀などの農産物では、品種数や流通形態が年々増加しており、限られたデータベースだけでは十分な識別が難しくなるケースもあります。
そのため、DNA検査を選定する際には、
・どの程度のデータベースを保有しているか
・継続的に更新されているか
といった点も、重要な評価ポイントになります。
データベースの規模から考える米DNA定性検査の選び方
米品種判別検査における「定性検査」とは、単一品種のもみや玄米、精米等に対し、想定以外の品種が入っていないかどうかを確認する検査です。
弊社では、国内最大規模となる677品種のデータベースを活用した米DNA定性検査を提供していますが、
今回、新たに「うるち436」というサービスを追加いたします(2026年6月1日より)。
これは、うるち米に対象を絞った436品種のデータベースによる定性検査です。
両者をそれぞれまとめると、「うるち436」は“うるち米に特化した実用型”、「677」は“最高精度を追求したフルスペック型”という位置づけとなります。
実用性とコストのバランスを重視した「定性検査うるち436」
下記のようなケースでは、「うるち436」が選択肢となります。
- 主にうるち米を扱っている
- 日常的な確認検査として利用したい
- コストを抑えながら運用したい
「436品種」でもデータベースは依然として大規模であり、実用上は十分高い識別能を備えています。
国内最大のデータベースを基にした最高精度の「定性検査677」
一方で、下記のようなケースでは、「定性検査677」が適しています。
- 酒米やもち米を扱っている
- 異品種混入リスクをより厳密に確認したい
- 対外的な品質の証明やクレーム対応に活用したい
「677」は国内最大規模のデータベースを基盤としており、より高い排他性を確保できます。
定性検査で異品種が確認された場合には?
定性検査で指定品種以外の混入が確認された場合には、
- どの程度混入しているのか(定量検査)
- 何の品種が混入しているのか(品種特定検査)
といった、さらなる調査が可能です。
定量検査および品種特定検査は、いずれも国内最大の677品種データベースをもとに実施しています。
万一問題が発生した場合にも、国内最大規模のデータベースを活用した高精度な検査により、原因調査をサポートいたします。